En Python 3 las cadenas se dividen en dos tipos. Las de texto con caracteres como elementos y las de bytes que representan una serie binaria de unos y ceros.
También haremos un repaso de las codificaciones de caracteres, ASCII, Latin y Unicode.
CADENAS DE TEXTO Y DE BYTES
Autor: Alberto Peiró
Labels: Tkinter, Python 3
Cadenas (Strings)
Cadenas de texto y de bytes
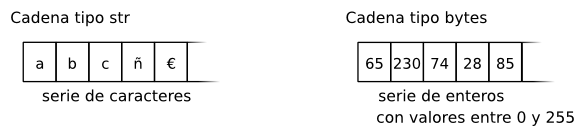
En Python 3.X hay definidos dos tipos de cadena. El tipo str para cadenas de texto Unicode y el tipo bytes para series de datos binarios.
Lo que define al primer tipo de cadena (tipo str) es que los elementos son caracteres, sin importar el número de bytes que necesite su representación.
>>> cadena = 'abc' # creación de una cadena str
>>> cadena
'abc'
>>> type(cadena) # comprobamos el tipo
<class 'str'>
>>> cadena[1] # tomamos un elemento
'b'
>>> type(cadena[1])
<class 'str'> # los elementos son cadenas de texto de un caracter
Mientras, una cadena de tipo bytes es una secuencia de enteros con valores entre 0 y 255 (o entre 0 y 0xFF en hexadecimal) que en el fondo están representando bits.
# Con b (de binario) construimos literales del tipo bytes
>>> serie = b'abc' # creación de una cadena bytes
>>> serie
b'abc'
>>> type(serie) # comprobamos el tipo
<class 'bytes'>
>>> serie[1] # tomamos un elemento
98
>>> type(serie[1])
<class 'int'> # los elementos son enteros!!!
Los elementos de una cadena de bytes son enteros y no debe confudirnos el hecho que cuando lo representa en pantalla se usen caracteres.
Figura 1. Cadenas tipo str y tipo bytes.
Por ahora todo muy sencillo. Pero las dudas comienzan cuando uno se pone a pensar "en modo programadro C" y se pregunta si la cadena 'abc', de caracteres ASCII, es equivalente a la serie de bytes b'abc'. La respuesta es que en Python son dos objetos de dos tipos completamente distintos. El uno son es secuencia de caracteres y el otro de bytes (o enteros). Por lo que intentar mezclarlos sería equivalente a operar directamente entre enteros y cadenas de texto (que acarrearía alguna conversión no explícita que por naturaleza evita Python).
>>> 'a' + 4
TypeError: Can't convert 'int' object to str implicitly
>>> 'abc' + b'abc'
TypeError: Can't convert 'bytes' object to str implicitly
Sin embargo, sí se puede convertir una cadena de texto en una de bytes y viceversa. Pero antes vamos a ver como se codifican los caracteres en un ordenador.
Códificación de caracteres
Hay varios estándares que hacen corresponder a cada símbolo un entero y la forma en que se almacenan en forma bytes.
El estándarASCII define los caracteres correspondientes a los valores entre 0 y 127 y que emplea todo un byte para almacenar cada caracter.
Otro estándar es el Latin-1 (o ISO-8859-1) en el que cada caracter también se representa por un byte. Pero en este caso se define una relación para los 255 valores posibles. De 0 al 127 son los mismos caracteres que ASCII y el resto se utiliza para incorporar otros caracteres occidentales como la ñ o las vocales acentuadas.
Como los 256 valores codificables por un byte no son suficientes para todos los caracteres utilizados en el mundo aparece Unicode, que utiliza varios bytes y distintas codificaciones. Es decir las distintas formas de guardar los enteros en bytes.
El más popular es UTF-8 que representa los caracteres con un número variable de bytes (lo que ahorra espacio). Para códigos entre 0 y 127 usa un byte, por lo que mantiene la compatibilidad con ASCII. Entre el 128 y 0x7FF emplea dos bytes (con algunos bits fijados para distinguirlos de los códigos de un solo byte). Y a partir del 0X800 en tres o cuatro bytes.
UTF-16 y UTF-32 tienen un tamaño fijo de dos y cuatro bytes respectivamente para todos los caracteres.
Para asentar lo anterior vamos a practicar en el intérprete de Python.
Disponemos de la función ord() que devuelve el númeral en Unicode del caracter, es decir algo así como la posición en la tabla de códigos. Su primo chr() hace el trabajo inverso, le damos un entero y nos devuelve el caracter correspondiente a ese código Unicode.
>>> # Valores Unicode de caracteres
>>>
>>> ord('a') # ordinal Unicode del caracter 'a'
97
hex(97) # obtenemos su representacion hexadecimal
'0x61' # cabe en un byte
>>> ord('ñ')
241
>>> hex(241)
'0xF1' # cabe en un byte
>>> ord('€')
937
>>> hex(937)
'0x3A9' # no cabría en un byte
>>> chr(98) # caracter Unicode correspondiente al número 98
'b'
No hay que confundir el código Unicode anterior con la forma en que son almacenados como bytes. Esto último depende de la codificación escogida ASCII, Latin-1, UTF-8... etc.
Tanto Latin-1 como UTF-8 mantienen la compatibilidad con ASCII. La representación como bytes es la misma.
>>> ord('ñ') # ordinal Unicode del caracter 'ñ'
241
>>> 'ñ'.encode('ascii')
UnicodeEncodeError: 'ascii' codec can't encode character '\xf1'
# Produce un error porque el caracter 'ñ' no tiene codificación en ASCII
>>> 'ñ'.encode('latin1')
b'\xf1' # es el hexadecimal f1
>>> 'ñ'.encode('utf8') # es compatible con la ASCII
b'\xc3\xb1' # es una codificación del caracter 'ñ' y no el hexadecimal de su ordinal
El caracter ñ no pertenece al estándar ASCII por lo que da un error.
Nota
'\xNN' es la forma con secuencias de escape (caracteres que escapan de ser interpretados) para introducir directamente un valor hexadecimal en cadenas de texto o de bytes.
Por ejemplo, para introducir el caracter de inicio de texto y fin de texto que se usa en comunicaciones y no podemos teclear directamente:
Si no se especifica una codificación en str.encode() o B.decode() se toma la que hay especificada en el sistema operativo. Normalmente será UTF-8 pero puede consultarse con el método sys.getdefaultencoding.